IA aplicada, capítulo 1: Introduciendo Redes Neuronales
- Artículos
- Data Science & IA
Este blogpost forma parte de una serie de 4 blogs, orientados a mostrar el impacto de la IA en las organizaciones. Esta primera entrada introducirá el marco teórico y la explicación técnica de IA, donde en los subsiguientes se definen y ejemplifican sus aplicaciones concretas.
Redes Neuronales: Introducción
Hoy en día, cada vez más se habla de modelos de inteligencia artificial (IA), cómo estos se podrían utilizar en la actualidad y cómo evolucionarán en un futuro cercano. Ejemplos de estos modelos son el surgimiento de ChatGPT, los autos autónomos, y la generación de videos e imágenes mediante texto. En las palabras de Bill Gates, “el desarrollo de la inteligencia artificial (…) cambiará la forma en que las personas trabajan, aprenden, viajan, reciben atención médica y se comunican entre sí. Industrias enteras se reorientarán en torno a ella. Las empresas se distinguirán por lo bien que la utilicen” (fuente).
En Brain Food, estamos alineados con esta visión y creemos en la inteligencia artificial como una herramienta que puede entregarle gran valor a las empresas, optimizando la eficiencia en distintos procesos al igual que aumentando las capacidades de los trabajadores.
La IA hace referencia a máquinas que imitan funciones cognitivas humanas para optimizar la resolución de problemas, entregando soluciones y respuestas eficientes. A través de la predicción y automatización, logra resolver tareas complejas que históricamente han sido realizadas por humanos (fuente).
Figura 1: Categorías de la Inteligencia Artificial (fuente)
Como se muestra en la Figura 1, la inteligencia artificial engloba tanto al Machine Learning como al Deep learning. Se denomina Machine Learning al conjunto de modelos matemáticos que logran aprender desde los datos. Por lo general, los modelos de este tipo de IA hacen uso de los datos mediante características generadas por el equipo tal como media, desviación estándar, entre otras. Es decir, es data estructurada donde cada registro describe alguna característica diseñada por humanos y, por ende, el desempeño que obtenga está directamente ligado a qué tan buena es la elección de estas. Por otra parte, existe una subárea del Machine Learning denominada Deep Learning, el cual hace uso de redes neuronales de 3 o más capas (fuente). Este tipo de IA se especializa en modelos de aprendizaje que no requieren que los datos se encuentren representados como características, sino que analizan los datos directamente, aprendiendo la mejor representación de éstos para resolver los problemas o tareas. La desventaja que tienen es que para aprender a resolver la tarea correctamente es necesario entregarles grandes cantidades de datos, de esta forma, logran aprender su representación correcta
El Perceptrón
Las redes neuronales fueron introducidas en 1957 por Frank Rosenblatt con su trabajo titulado regla de aprendizaje del perceptrón (“Perceptrón Learning Rule”). El perceptrón es la unidad básica que compone las redes neuronales y representa una neurona artificial que permite detectar patrones en los datos. Éste consiste en un conjunto de parámetros, representados como en la Figura 2, los cuales realizan una ponderación de las entradas que luego es sumada. Este valor sumado indicará, en caso de ser positivo, que la neurona está activada, o en el caso contrario, apagada. El tipo de entrenamiento de estos modelos es a través de entrenamiento supervisado y se produce con el algoritmo de retro propagación de gradiente (backpropagation en inglés) (fuente), que permite ajustar los parámetros del modelo.
Figura 2: Figura que muestra el funcionamiento del perceptrón (fuente)
Del Perceptrón a Redes Neuronales
A pesar de que el perceptrón es un modelo que aprende de los datos, solamente puede aprender funciones linealmente separables. Lo anterior hace que este tipo de modelo sea bastante limitado al momento de ajustarse a datos que no sigan una separación lineal.
Para abarcar estas limitaciones se creó el modelo de red neuronal, representando en la Figura 3, el cual su nombre de su inspiración laxa en la neuro ciencia y cómo es que cada perceptrón de la red cumple un rol análogo al que realizaría una neurona en las conexiones neuronales. Las redes neuronales son grafos acíclicos que se componen de capas representadas vectorialmente, donde las hileras verticales representan las capas de una red y los círculos, los perceptrones descritos anteriormente. Al unir varios perceptrones y agregarles una función no lineal, es posible abarcar problemas que no sean linealmente separables.
Figura 3: Figura que muestra la representación de las redes neuronales
Como se puede observar en la Figura 3, las entradas al modelo se encuentran a la izquierda de la figura (marcada por la letra x) y la salida de éste se encuentra a la derecha. La capa que recibe la entrada se le denomina capa de entrada, a la capa final se le denomina salida y a las capas intermedias se les denominan capas ocultas. En este caso el modelo tiene dos capas ocultas.
Una parte importante de estos modelos es la función de activación, que hace referencia a la función que genera la salida de la red neuronal. Su principal objetivo es introducir “no-linealidad” en el modelo, permitiendo así que, al momento de apilar capas de una red, ésta pueda aprender representaciones cada vez más complejas.
Al momento de construir un modelo de red neuronal es relevante considerar sus híper parámetros. Estos constituyen la definición de la cantidad de neuronas de cada capa, la cantidad de capas y la función de activación. Para el caso de esta última, hay una gran cantidad de posibilidades lo que hace que la elección de esta sea una definición importante que tendría impacto en el resultado del modelo.
La ventaja que agrega el uso de redes neuronales profundas nace de la idea de que las distintas capas y la cantidad de neuronas que tienen permiten representar de mejor manera el problema, incurriendo en un trade-off entre representación y tiempo de entrenamiento. De este modo, arquitecturas diferentes modificarán el tipo de características que podamos extraer de los datos.
Teoría detrás de las redes neuronales
Desde un punto de vista más teórico, las redes neuronales aseguran que el modelo pueda efectivamente aprender y aproximar una función, lo cual se debe a que una red con una capa oculta es un aproximador universal que se deduce desde el Teorema de Aproximación Universal (Hornik, Stinchcombe & White, 1989). Éste establece que una red neuronal multi capa, que tenga al menos en una capa oculta una función de comprensión [1] como función de activación puede aproximar cualquier función en un conjunto cerrado y acotado de ℜ (Goodfellow, Bengio & Courville, 2016).
En otras palabras, este teorema significa que una red neuronal es capaz de representar cualquier función que se quiera aprender siempre y cuando esta sea lo suficientemente grande. Lamentablemente, esto no asegura que el algoritmo de entrenamiento de la red sea capaz de encontrar dicha solución, ya que, dada la inicialización aleatoria de estas, puede ser difícil generar los parámetros necesarios puede verse afectada por la obtención de mínimos locales durante entrenamiento.
Ahora, al momento de definir la estructura de una red hay que considerar la profundidad de esta. Como intuición general, al elegir una red neuronal profunda la suposición que se está haciendo sobre el problema es que la función que se trata de aproximar se puede reconstruir como una composición de funciones más simples. Empíricamente, se ha visto que modelos más profundos tienden a tener mejor poder de generalización en una gran variedad de tareas (Goodfellow, Bengio & Courville, 2016).
Redes Convolucionales: ¿Qué es una imagen?
Otro tipo de red neuronal son las redes convolucionales (CNN), las cuales son por excelencia la manera en que hoy en día se analizan imágenes. Una imagen es una representación en 2D de cualquier cosa que pueda ser capturado por una cámara o generado mediante computadora. Las imágenes, en el ámbito del procesamiento de imágenes, se representan mediante matrices, donde cada píxel o punto de la matriz tiene un valor entre 0 y 255 (0 siendo un píxel apagado y 255 un píxel completamente encendido). Dependiendo si la imagen es a color, una imagen puede estar representada en 3 matrices o en una sola. En caso de que esta esté en blanco y negro las imágenes son representadas solamente por una matriz y las tonalidades se verán representadas por el valor que tomen sus pixeles entre 0 y 255. Si la imagen es a color, entonces será representada con 3 matrices, llamados canales, donde cada una representa las tonalidades de rojo, verde y azul. A esto se le denomina canales RGB (por sus siglas en inglés).
Definiendo la Red Convolucional
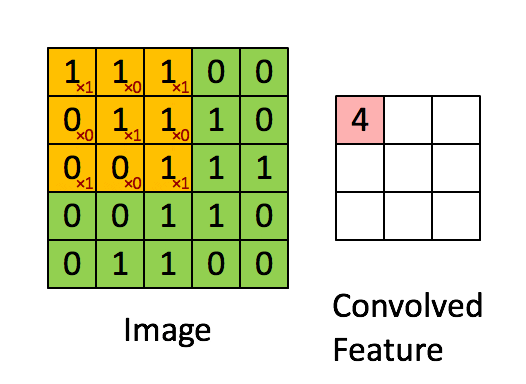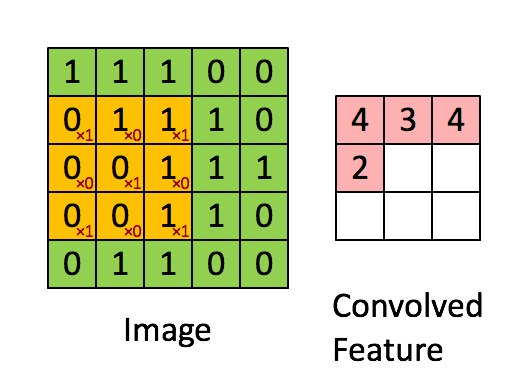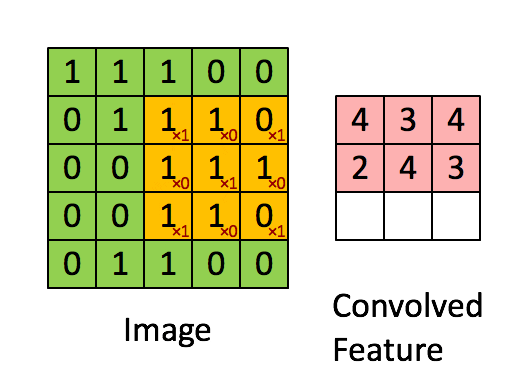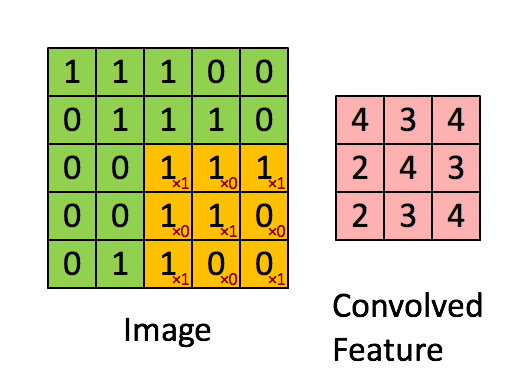
Las CNN están diseñadas para procesar datos en forma de grilla. Estos modelos son simplemente redes neuronales que en vez de hacer uso de la multiplicación matricial hacen uso de la convolución [2] que es una operación matemática lineal definida sobre una entrada Ι por un kernel o filtro Κ (Goodfellow, Bengio & Courville, 2016). En la Figura 4, se puede observar un ejemplo de cómo se vería una convolución.
Figura 4: Figura de una convolución (fuente)
{kind=link}
El uso de la convolución tiene una ventaja sustantiva al momento de entrenar estos modelos para analizar imágenes (Goodfellow, Bengio & Courville, 2016). En primera instancia, los kernel son más pequeños que la imagen. Estos kernel se aplican a la completitud de la imagen, lo cual genera que se puedan identificar características comunes a través de la imagen entera [3]. La finalidad del entrenamiento de las redes convolucionales es poder encontrar los kernel necesarios para caracterizar la imagen, por lo que, al aplicar el mismo filtro a distintas secciones de ésta, se deben aprender menos parámetros para resolver el problema, lo cual lo simplifica. Las capas de convolución pueden ser complementadas con stride, padding o pooling, métodos que se encuentran más allá del alcance de este blog (más información aquí).
Gracias al uso de canales, es posible aplicar más de un filtro en las capas convolucionales. Como se vio anteriormente, una imagen puede tener canales dependiendo de si se encuentra a color o en blanco y negro. Esto hace que la convolución en realidad se realice a través de todos los canales de la imagen, haciendo que los valores que capture el kernel sean condensados en un solo punto de la imagen resultante, como muestra la Figura 5. Siguiendo este mismo principio es que una capa de red convolucional puede aplicar varios filtros al mismo tiempo, ya que la salida tendrá tantos canales como filtros se hayan aplicado. Lo anterior permite que por cada capa se pueda representar de mejor manera los resultados.
Figura 5: Funcionamiento de los filtros en una red convolucional (fuente)
Utilidad de las Redes Convolucionales
Las redes convolucionales son utilizadas esencialmente como extractor de características de imágenes. Su finalidad es (después de aplicar una serie de capas convolucionales) obtener un vector que pueda caracterizar los aspectos más importantes de una imagen. Una vez realizado esto, las salidas se pueden analizar utilizando el algoritmo de Machine Learning de elección del data scientist para resolver la tarea.
La principal ventaja de las CNN se encuentra en poder describir la imagen con estas características, ya que, si estas no existieran, habría que elegirlas a mano. Las redes convolucionales han generado una revolución en el procesamiento de imágenes, logrando así detección de distintos objetos, reconocimiento facial, detección de situaciones de peligro que de otra manera no podrían ser analizadas de manera automática. En el siguiente blog se verá un ejemplo donde se aplicarán estas redes convolucionales a la detección de muestras de sangre para clasificar la existencia de cáncer en estas
Usos en la industria
A través de este blog, se ha descrito una introducción a los modelos de redes neuronales convencionales, en donde se explicaron sus principales características. Este tipo de redes constituyen la base para modelos más complejos que son utilizados hoy en día, tales como redes recurrentes y modelos de atención. La base de su entrenamiento y su evaluación siguen la misma lógica haciendo que los conceptos vistos en este blog sean importantes al momento de entender cómo es que aprenden las redes neuronales.
Por último, la IA y su desarrollo han generado un gran efecto en la sociedad en que vivimos, logrando estar inmerso en nuestra realidad. Hoy en día estas están siendo utilizados tanto para modelos autónomos de autos, reconocimiento de rostros en los teléfonos celulares, chatbots en call centers, detección de situaciones de peligro en faenas productivas, motores de búsqueda, entre otros. El desarrollo de estos modelos se vuelve fundamental para poder potenciar la industria y hacer que el potencial del hombre se enfoque en crear más que en la realización de actividades rudimentarias.
En las siguientes entradas profundizaremos en este tema y veremos más ejemplos de nuevas aplicaciones de IA en las organizaciones.
[1] En el contexto de las redes neuronales, una función de compresión se refiere a funciones cuyo valor esté limitado a cierto rango de valores, esto podría ser 0 y 1 o también entre -1 y 1.
[2] En realidad, para ser más rigurosos las redes neuronales convolucionales hacen uso de la correlación cruzada, esto en la práctica no genera diferencias importantes ya que el kernel es aprendido por la red y además no se necesita la propiedad conmutativa de esta matriz.
[3] Acá hay más información para ver distintos tipos de kernels y el efecto que tienen en imágenes: link
Referencias
- Gates, B. (2023, March 21). The age of ai has begun. gatesnotes.com. https://www.gatesnotes.com/The-Age-of-AI-Has-Begun
- What is deep learning?. IBM. (n.d.). https://www.ibm.com/topics/deep-learning
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Control Signal Systems 2, 303–314 (1989). https://doi.org/10.1007/BF02551274
- (2023, January 18). Perceptron: Concept, function, and applications. DataScientest. https://shorturl.at/dEOY9
- Hornik, K., Stinchcombe, M., & White, H. (1989). Multilayer feedforward networks are universal approximators. Neural Networks, 2(5), 359–366. doi:10.1016/0893-6080(89)90020-8
- Shivamb, B. (2019, January 17). 3D convolutions : Understanding + use case. Kaggle. https://www.kaggle.com/code/shivamb/3d-convolutions-understanding-use-case
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
- Nouri, D. (n.d.). convolution gif. danielnouri.org. Retrieved from https://media.giphy.com/media/i4NjAwytgIRDW/giphy.gif.
- (2020). Backpropagation Details Pt. 1: Optimizing 3 parameters simultaneously. YouTube. Retrieved October 19, 2023, from https://www.youtube.com/watch?v=iyn2zdALii8.
- Kingma, D. P., & Ba, J. (2015). Adam: A Method for Stochastic Optimization. In Y. Bengio & Y. LeCun (Eds.), 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings. Retrieved from http://arxiv.org/abs/1412.6980
- Lahtela, M., & Kaplan, P. (Provenance). (n.d.). ES. Amazon. https://aws.amazon.com/es/what-is/neural-network/
- Arimateia Batista Araujo-Filho, J., Júnior, A. N. A., Gutierrez, M. A., & Nomura, C. H. (2019). Artificial Intelligence and Cardiac Imaging: We need to talk about this. ARQUIVOS BRASILEIROS DE CARDIOLOGIA – IMAGEM CARDIOVASCULAR, 32(3). doi:10.5935/2318-8219.20190034. https://www.researchgate.net/publication/334208581_Artificial_Intelligence_and_Cardiac_Imaging_We_need_to_talk_about_this